
Background
In previous articles in this series on A Light Touch Regulatory Framework for AI we have argued for the need for a ‘light-touch’ regulatory framework for technology solutions using AI, with a primary focus on transparency obligations which would be dependent on the human impact of the AI solution.
We suggest that the key components of the Light Touch Regulatory Framework for AI should be organized around a transparency requirement relating to registrable (but not necessarily approved) AI solutions – with the assessment of the required level of transparency focusing on two elements:
- technical assessment – a quality, rational and sensibility assessment of the AI solution, including the data sets used; and
- human importance assessment – relating to the impact on the fundamental rights of individuals and the importance to the state.
Our second and third articles in this series focused in more detail on the transparency requirement through examining the classification of AI solutions based on assessment of the technical quality and the human importance assessments of the solutions.
This article looks in more detail at the purpose and use of transparency in the context of the regulation of AI solutions. We examine the question of how transparency should operate in this context. The UK Royal Society has identified that the transparency of AI solutions comes in many forms.[1] In the regulatory context we suggest that the scope and level of transparency should be sufficient to enable individuals and civil society bodies to review, analyze and critique AI solutions so that potential or actual harms can be identified. We consider that, except for the most invasive deployments of AI, publicity, debate and persuasion are likely to be more effective in “policing” responsible AI than bureaucratic regulatory approvals system.
In the AI context, transparency and explainability are made complex because of the inherent difficulty of human understanding of advanced AI algorithms, particularly where the AI solutions have self-learning capabilities. In the middle section of this article, we examine these developments in more detail.
For transparency to have effective power, processes need to be developed so that transparency (coupled with publicity, debate and persuasion) becomes an effective mechanism for “policing” responsible AI. In the final section of this article we review some lessons that should be learned from the public consultation process for the use of algorithms for UK school exams results in 2020 as a result of the COVID-19 crisis. AI solutions were not involved in these processes but the consultation process that was carried out gives some important indications for an effective transparency-based regulatory mechanism for AI solutions.
Transparency and explainability are the two principles that are most studied in the recent literature related to AI ethics[2]. These two concepts are closely related but transparency may not always lead to explainability. Transparency can be limited so that explainability is not achieved. Whilst, as we discuss in this article, explainability is a particular challenge in the context of AI solutions, there is also a need to consider how transparency can be effective mechanism to “police” responsible AI.
Transparency in a Regulatory Context
Background
The UK Royal Society has identified a range of terms that are used to describe AI characteristics as follows:
- interpretable – some sense of understanding how the technology works;
- explainable – a wider range of users can understand why or how a conclusion was reached;
- transparent – some level of accessibility to the data or algorithm;
- justifiable – there is an understanding of the case in support of a particular outcome; or
- contestable – users have the information they need to argue against a decision or classification. [3]
In the context of an effective legal framework for the regulation of AI solutions transparency needs to be sufficient to enable individuals and civil society bodies with a reasonable level of skill and experience to be able to understand the AI solution sufficiently well to be able to identify if harms are likely to arise as a result of the usage of the AI solution. This links in closely with the Royal Society concepts of explainability and contestability – see above.
In the AI regulatory context explainability creates particular challenges. Regulatory frameworks tend to be based around a straightforward cause and effect models. AI solutions are subject to the classic “back-box” problem. Yavar Bathee has commented:
It may be impossible to tell how an AI that has internalized massive amounts of data is making its decisions. For example, AI that relies on machine-learning algorithms, such as deep neural networks, can be as difficult to understand as the human brain. There is no straightforward way to map out the decision-making process of these complex networks of artificial neurons. Other machine-learning algorithms are capable of finding geometric patterns in higher dimensional space, which humans cannot visualize. Put simply, this means that it may not be possible to truly understand how a trained AI program is arriving at its decisions or predictions.[4]
In this sense, a regulatory framework for AI needs to be cognisant of the inherent restrictions imposed by AI. There may be instances where it will be unrealistic and futile to attempt to explain the unexplainable. This does not mean that transparency is not required. In the next section of this article we explore some of the inherent features of advanced AI algorithms that create difficulties for meaningful explanations.
From a regulatory perspective the key concerns relate to the outputs of AI solutions. The regulatory framework needs to require sufficient transparency so that AI solutions can be meaningfully analysed and reviewed to identify the likelihood of outputs that will cause harms, including through algorithmic bias. There are parallels with scientific explanations which develop over time through scientific investigation and scientific questioning and scrutiny. These parallels indicate that less than full explainability can be extremely valuable. Isaac Newton’s theory of gravity did not fully explain the cause of gravity. Newton recognised that his theory observed and correlated gravitational influences at both the astronomical and everyday levels. His theories simply explained the behaviour of bodies with mass under the influence of gravity. Even so, they were a crucial element in the advancement of scientific understanding. In an AI regulatory framework, the level and scope of the required transparency should be focused on the outputs of the AI solutions in order to enable individuals and civil society bodies to review and assess the consequences of these outputs.[5]
Newtonian Principles of Explainability
Taking the scientific explanation comparison a step further, the situation is more complicated as the “black box” problem indicates a transition from Newtonian to Relativistic concepts of explainability. Newton’s scientific concepts were based on a cause and effect model of causation. For example, the Newton’s second law of motion as described in his Philosophiae Naturalis Principia Mathematica. Figure 1 (see below) states that the acceleration of an object as produced by a net force is directly proportional to the magnitude of the net force, in the direction of the net force, and inversely proportional to the mass of the object. Hence the rate of change of the momentum of a body (acceleration) will always be fully predictable and can be accurately calculated given the net force and mass of the object, which are both predictable, deterministic and hence such outcome is repeatable. This is a pure causation model. Similarly, most legal theories also build on concepts of causality and responsibility where an initial state is subject to actions leading to outcomes that are regarded as predictable and repeatable.

Figure 1. Newton three laws of motion (Lex I-III) from Philosophiae Naturalis Principia Mathematica (Isaac Newton 1687)[6]
Newton’s three laws of motion, together with his law of gravitation, provide a deterministic and predictive explanation of motion of everyday macroscopic objects under everyday conditions. However, it breaks down when applied to objects extremely high speeds (factors of speed of light) as well as particle level objects (atoms, electrons). There is an analogous breakdown with legal theories when applied to advanced AI solutions. Legal theories result in unfavourable outcomes when dealing with AI solutions, requiring a different approach. In the physical world the solution is Einstein’s Special Theory of Relativity and Quantum physics.
Relativistic Principles of Explainability
In the context of the transparency of AI solutions there needs to be a “quantum leap” in the concept of explainability. As a result of the “black box” problem, it may not be possible to fully predict an output from the input states of an AI solution. Outputs from AI solutions are likely to be essentially statistical and probabilistic, rather than definitive and predictive. They may not be fully explainable in a deterministic, cause, predictive, and effect sense. With AI solutions, especially advanced AI solutions, explainability is more relativistic: advanced AI solutions of any degree of complexity operate on the basis of statistical models that are probabilistic. These may accurately predict at the macro level (e.g. sets of population and civil society bodies) but may give considerable uncertainty at the micro-level (e.g. individuals).
These problems with AI explainability do not mean that transparency as the basis for the regulation of AI should be abandoned. There is, of course, a need for realism in the level of explainabilty that that can be achieved. The Royal Society suggests three approaches:
- Inherently interpretable models: Use models whose structure and function is easily understood by a human user, eg a short decision list.
- Decomposable systems: Structure the analysis in stages, with interpretable focus on those steps that are most important in decision-making.
- Proxy models: Use a second – interpretable – model which approximately matches a complex ‘black box’ system.[7]
Each of these potential explainability solutions involves an essential simplification of the underlying complexity of the AI solution. Some level of simplification may be inevitable in order for humans to develop an understanding of the operation of an AI solution.[8] The need for simplification leads to a requirement for discussion, debate and dialogue as an inherent component in a regulatory framework for AI based around transparency. In this article, we emphasise that AI solutions using advanced algorithms are by their intrinsic nature outside the possibility of full explainability. However, AI solutions should be scrutinised and challenged in a relatively open forum so that problems can, hopefully, be identified in advance and overcome.
In the health AI context the concept of “effective contestability” has been suggested.[9] We suggest that this concept could be extended more generally for AI solutions, not just in the healthcare context. Ploug and Holm comment:
“In considering AI diagnostics we suggest that explainability should be explicated as “effective contestability”. Taking a patient-centric approach we argue that patients should be able to contest the diagnoses of AI diagnostic systems, and that effective contestation of patient-relevant aspect of AI diagnoses requires the availability of different types of information about:
1) the AI system’s use of data,
2) the system’s potential biases,
3) the system performance, and
4) the division of labour between the system and health care professionals.
These concepts provide a useful road-map for explainability in the context of a regulatory framework for AI solutions. Explainability needs to be considered on a holistic basis, taking account of and building on these four elements. These concepts and the understanding of explainability and effective contestability need to be fed-back in the concept of required transparency for AI solutions in the context of a regulatory framework for AI.
Before examining the concept of effective contestability in more detail in the context of a real-world example of transparency in practice, we provide a scientific analysis of the intrinsic problems around explainability of AI solutions based on advanced AI algorithms.
Advanced AI Algorithms
Background
Advanced AI algorithms provide particular challenges for the explainability and contestability of AI solutions. We suggest a human centric approach to understand what advanced AI algorithms are, in order to identify problems that can be encountered during their design, development and deployment. This gives a better understanding of how to assess existing legal theorems and how our Light Touch Regulatory Framework for AI can be used.
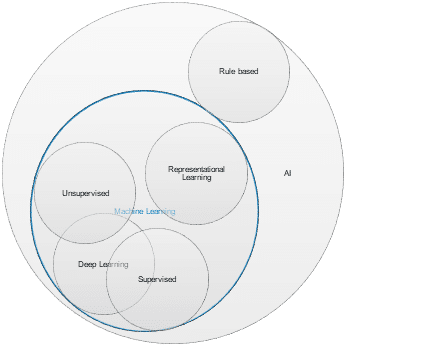
Figure 2: Breakdown of Artificial Intelligence (AI) Algorithms
Artificial Intelligence (AI) can be described in general terms as a discipline that involves making computers to do tasks that humans can do, specifically tasks that need intelligence. The AI demonstrated by machines, either a software program or a robot, does not involve consciousness, common sense, intuition or emotions that are typical of human intelligence.
AI can be broken down broadly into rule-based learning, machine learning, representation learning and deep learning. Machine learning algorithms include representation learning (e.g. autoencoders) and “deep learning” (see figure 2). Generally, machine learning algorithms can be either supervised learning or unsupervised learning. Today, supervised learning, specifically deep learning based supervised learning, forms the majority of AI solution deployment. We regard most of the algorithms that fall within the category of machine learning (including deep learning algorithms – either supervised or unsupervised) as advanced AI algorithms due to their complexity and the probabilistic nature of their approach to learning.
Deep learning
Deep learning algorithm design has been inspired by the brain and collective learning (training) and decision making (inference) through collections of neurons, a unit of compute. Neuroscience forms the basis of how to form the structure for, and interconnect (neural network) between, the neurons to work together to solve a problem. A single deep learning algorithm can solve many different problems.
An animal becomes intelligent using an organic brain when many of the brain’s neurons work together, interconnected in a complex array, the ‘layer’. An individual neuron by itself is not of much use. A multi-layered neural network algorithm is called a deep neural network or just deep learning. An example of a neural network is convolutional neural network, commonly used for image related training and inference.
Deep learning can be supervised or unsupervised. From a human centric perspective of describing unsupervised learning, these deep learning algorithms don’t require human intervention to tag or annotate data. Simply put, tagging/annotating data is needed to extract ‘features’ to identify the basic building block of the environment where the learning need to be done. In other words, tagging/annotating is needed to extract information from a data set that will be used to train (supervise) a deep learning algorithm. The deep learning algorithms requiring such ‘supervisors’ are called supervised learning deep learning algorithms. For simplicity, we call supervised learning deep learning algorithm as supervised learning algorithm and unsupervised learning deep learning algorithm as simply unsupervised learning algorithm.
Supervised learning algorithms
Historically, supervised learning algorithms were constrained by the compute, storage and data available to build, run and maintain such systems at a large scale. There have also been marginal changes to the algorithm itself used to train large scale AI solutions using supervised learning. Nevertheless, the fundamental basis of supervised learning algorithm has not altered to any significant over many years. The majority of the AI solutions that use deep learning are based on supervised learning, where the amount and quality of the data determines the accuracy of the results. Supervised learning involves training to create a model that is then deployed to generate the final results.
Some recent issues with supervised learning algorithms have shown that even if data quality is maintained with sufficient data representation to remove biases and boundary conditions in the data through careful annotation and sufficient scale for data collection, the model generated may not be reproduced if the training is done again either with the same data or new data sets. Specifically there are problems of:
- Underspecification: Even if a training process can produce a good model, it could provide a bad one because the solution is unable to detect the difference. [10]
- Data shift: Training fails to produce a reasonable model if the training data is divergent from the real world data.
This means that it is not possible to provide full predictability to the results, which will restrict transparency and explainability of these algorithms.
Unsupervised learning algorithms
The best approach to build AI solutions is not the supervised learning, data driven approach being dominant today in the industry. Instead, unsupervised learning, moving from static to dynamic models, and more raw generalized data than labelled data is preferable. Further, for unsupervised learning algorithms human intervention to tag/annotate data is not needed, making these algorithm much more scalable and robust if designed and deployed properly.
The Man and Machine
A similar approach to building machines that learn like a child was proposed by Alan M. Turing during October 1950 in his paper on Computing Machinery and Intelligence in the journal of philosophy, Mind.[11]
We cover two areas from his paper that are relevant in this context and can help us understand limitations of a predictive system and legal theorems based solely on predictions (as opposed to probabilities). As noted below, a machine can be a physical machine that integrates software and hardware or a software only solution that implements an algorithm – a software machine.
A Machine that behaves like Man[12]
Turing:
“It can also be maintained that it is best to provide the machine with the best sense organs that money can buy, and then teach it to understand and speak English. This process could follow the normal teaching of a child. “
Turing also provided details about the Imitation Games (the “Turing Test”) to test how to gauge a machine ability for intelligence and the ability to be indistinguishable from a human being. Such machines were theoretical at that time due to compute and memory limitations. This is not the case today. More important, the machines as described by Turing in 1950 and possible today in 2021 are probabilistic machines, just like a man, where all possible outcomes are not predictable. A good example is Generative Pre-trained Transformer 3 (GPT-3), an autoregressive language model that uses deep learning to produce human-like text from OpenAI[13]. Full transparency and explainability in these tools are not feasible.
Predicting behavior of Man and Machine
Turing:
“It is not possible to produce a set of rules purporting to describe what a man should do in every conceivable set of circumstances.”
Turing mentioned the ‘rules of conduct’ and ‘laws of behaviour’ that govern what we should do and what we can do. Rules of conduct are in-line with the Napoleonic code that forms the basis of legal systems in many parts of the world. The laws of behaviour are in-line with the Newton’s Law of Motion we covered earlier as well as being described scientifically by human physiology and psychology.
Turing also pointed out that:
“To attempt to provide rules of conduct to cover every eventuality, even those arising from traffic lights, appears to be impossible. With all this I agree.”
It was clear from his arguments from 1950 and hold true even now that a human cannot be a machine and a machine, just like humans, can be unpredictable.
Even if we are able to come up with laws similar to the ‘rules of conduct’ and ‘laws of behaviour’ for machines, we still can’t predict all possible outcomes. Hence, they will still have a probabilistic outcome. This is obvious for advanced AI algorithms where ‘rules of conduct’ and ‘laws of behaviour’ are themselves probabilistic, for example in an unsupervised learning algorithm. Even for complex rule-based algorithms, this may very well be the case.
Turing:
“I have set up on the Manchester computer a small programme using only 1000 units of storage, whereby the machine supplied with one sixteen figure number replies with another within two seconds. I would defy anyone to learn from these replies sufficient about the programme to be able to predict any replies to untried values”
To summarize, for advanced AI solution, an expectation of full explainability and transparency is neither possible nor reasonable. Deep learning algorithms, especially, have some level of intuition and replicate to a certain degree how the human mind thinks and makes decision. Advanced AI solutions do not provide a clear logic or a path on how a decision may have been derived.
We presented clear scientific evidence that an AI regulatory framework should focus on the outputs of the AI solutions, especially for advanced AI solutions. Instead of the Newtonian principles of predictability and repeatability based on causal inputs, a legal framework for the assessment of AI solutions should focus on a relativistic principle of explainability and a level of transparency in a more human context, focusing on discussion and dialogue on the safety and acceptability of AI solutions. To keep the scope of a legal framework as broad as possible, the same framework should cover both AI and advanced AI solutions. If a legal framework works for advanced AI solutions, it will also work for AI solutions generally.
In the next section of this article we focus on an example of transparency in practice and some lessons learned from an extensive consultation process which failed to recognise the extensive human problems that would result from the use of an algorithmic-based solution.
Transparency in Practice
UK School Exam Results 2020 – Ofqual Consultation Process
The COVID-19 pandemic resulted in the cancellation of the 2020 A-Levels exams in UK high schools in England, Wales, Scotland and Northern Ireland. Instead, an algorithm was used to provide these grades.[14] The process carried out by the UK government (through Ofqual, its Office of Qualifications and Examinations Regulation) caused a public outcry when the results were published in August 2020. The approach was widely regarded as being fundamentally unfair. Many students were awarded lower grades than their schools had predicted. The algorithm used by Ofqual to assess the results gave a significant degree of weight to the historic performance of the school or college that the student attended. If the school or college had a poor historic track record it counted against high achieving students so that their exam results were marked down.
There was no AI involved in the Ofqual school exams results assessment process. Even so, the process is relevant for the purposes of this article as Ofqual carried out a public consultation exercise in April 2020 which provided considerable transparency in the use of the algorithms for the assessment process. This consultation process provides insights into and lessons learnt for the conduct of transparency processes for AI solutions.
The consultation exercise was carried out at the level of the principles underlying the algorithms, rather than the publication of the algorithms themselves. There was a considerable response to the consultation (over 10,000 responses). The issue which caused the controversy related to the use of the previous performance of the schools and colleges within the algorithm to decide the student’s grades. On this issue Ofqual asked a question on the extent to which “statistical standardisation which emphasises historical evidence of centre [schools and colleges] performance given the prior attainment of students is likely to be fairest for all students”. 54% of respondents said that they agreed or strongly agreed with this question and 33% said they disagreed or strongly disagreed.
Despite the clear majority of respondents agreeing that the prior performance of schools and colleges should be taken into account in the assessment of students exam results, the Ofqual consultation analysis acknowledged that “some respondents told us that they were concerned that such an approach would be unfair to individuals who might have excelled this year and whose grades would be affected by the poor performance of their predecessors. A statistical approach will mean that an individual student’s grade will be informed by their position in the centre’s rank order for that subject, their prior attainment where available, and the centre’s past performance.
Ofqual responded to these concerns by commenting that students that would be impacted in this way could retake the exams in Autumn 2020. This suggests that they considered that there would be a small minority of students that would be affected and that the harm that they recognised would occur to these students did not invalidate the overall approach. It is surprising that neither Ofqual nor the Department of Education recognized the likelihood of significant public controversy resulting from the negative impact on even a small number of students being marked down in these important public exams. In retrospect, it is evident that there would be a public outcry about students being marked down in their exam results because of their school’s previous underperformance. The consequences of being marked down is clearly a high impact human issue as students were likely to be (and some were) denied their university choice.
If Ofqual had adopted the approach to transparency proposed in these articles (where issues with a high human impact are given greater attention) Qfqual would have recognized the likely concerns and could have made changes to avoid the problems. Even though the majority of respondents to the consultation agreed with Ofqual’s suggestion, under our proposed approach, this high human impact issue would have been reviewed and considered in more detail. It is likely that the harm that would result to a small number of students from the proposed approach would have high-lighted the issue as a “red-flag” concern that would have been addressed, either within Ofqual or referred to Government Ministers for attention. Instead, the issue appears to have been “brushed under the carpet” with no changes being made. Identifying and addressing high human impact concerns should have been a key aim of the Ofqual consultation exercise.
The UK schools’ exams fiasco indicates that transparency on its own will not necessarily be sufficient to avoid harms occurring in practice. As well as transparency, there is a need for responsiveness and openness to comments that are made, with a focus on issues that have a high human impact. The incident shows that the responses of the majority may not be correct. A small number of comments may highlight significant problems. Of course, in the end public debate and public pressure did result in changes being made. Following the publication of the results, the UK government was forced by the public response to make a change within a week and abandoned the algorithm-based approach. It would have been preferable, both for the students and Ofqual, if the consultation process had been sufficiently effective to identify the problems in advance (which it did) and then to provide a framework so that the identified problems would be resolved.[15]
In passing, the algorithms used to determine school exam results do not need to be complex. An alternative to the Ofqual approach was used in San Francisco. A California school district in October 2020 put forward a recommendation that admission to Lowell High School would be made through a random lottery for the fall 2020, instead of admission based on grades or test scores. It is arguable that a random lottery is fair as a random lottery means that every student has equal odds of being admitted. This approach was needed for the similar reason as in the UK. San Francisco district officials did not have a way to assess students due to lack of grades from spring semester and the inability of the district to administer standardized tests during the pandemic.[16]
Lessons learned
In general terms, due process and proper assessment of AI solutions in a regulatory framework based on transparency should be achievable if the required level of transparency provides:
- an adequate level of detail about the AI solution to provide explainability and effective contestability; and
- the level of public involvement and debate around these issues is sufficient to apply pressure to the organization deploying the AI solution so that the deploying organisation will respond and make changes where harms are identified in advance and where harms occur in practice.
We recognise that transparency in its own will not be sufficient. Transparency will only be effective if there is sufficient public interest and debate in these issues so that organizations deploying AI solutions believe that it is in their interests to respond to identified concerns and to make changes where necessary.
Although the predictive algorithm used for determining the grades for A-Levels exams administered for UK schools or the randomized algorithm Lowell High School in the US are not AI solutions, we argue that the framework outlined in these articles can be generalized for these scenarios. Based on our framework, the AI Index for predictive algorithm used for determining the grades for A-Levels exams would have been A or A-, which would have required notifications, an impact assessment and, potentially, prior approval. A proper impact assessment focusing on the potential human impact of the application of the algorithms would have identified the problems in more detail and this would have helped to mitigate some of the issues before deployment of the algorithm.
For the simple randomized algorithm proposed by San Francisco district officials for admission to Lowell High School, notification requirement for rationality and sensibility would enable the right level of transparency, discussion and decision for the use of such algorithm.
Whilst at first sight, the failure of the Ofqual consultation process to recognize the problems in advance may appear to undermine the usefulness of transparency as a key element in the regulation of AI solutions, when the process used by Ofqual is examined in more detail a number of useful lessons can be learnt which better inform a regulatory framework for AI solutions focused around transparency.
In the next article in this series we will focus on the legal structures that are needed to underpin the proposed regulatory framework.
Roger Bickerstaff – Partner, Bird & Bird LLP, London and San Francisco
Aditya Mohan – CEO, Skive.It, San Francisco
[1] See “The Royal Society, Explainable AI”: the basics”, https://royalsociety.org/-/media/policy/projects/explainable-ai/AI-and-interpretability-policy-briefing.pdf
[2] See – Principled Artificial Intelligence by Harvard University, http://nrs.harvard.edu/urn-3:HUL.InstRepos:42160420
[3] “The Royal Society, Explainable AI”: the basics”, p.8
[4] Yavar Bathaee, “The Artificial Intelligence Black Box and The Failure of Intent and Causation” https://jolt.law.harvard.edu/assets/articlePDFs/v31/The-Artificial-Intelligence-Black-Box-and-the-Failure-of-Intent-and-Causation-Yavar-Bathaee.pdf
[5] See e.g. Richard S. Westfall, “Never at Rest: A Biography of Isaac Newton”
[6] https://www.loc.gov/item/28020872/
[7] See The Royal Society, Explainable AI”: the basics”, p.13
[8] There is a clear risk that of over-simplification. The example of the UK schools exams fiasco (discussed below) indicates that transparence at too high a level of simplification may make it more difficult to identify potential problems even if there is considerable transparency.
[9] Thomas Ploug and Soren Holm, “The four dimensions of contestable AI diagnostics – A patient-centric approach to explainable AI”, https://www.sciencedirect.com/science/article/pii/S0933365720301330
[10] https://www.technologyreview.com/2020/11/18/1012234/training-machine-learning-broken-real-world-heath-nlp-computer-vision/
[11] https://doi.org/10.1093/mind/LIX.236.433.
[12] In this context, the term “Man” at the time of Turing was understood to refer to people of all genders.
[13] https://arxiv.org/abs/2005.14165
[14] https://www.wired.com/story/an-algorithm-determined-uk-students-grades-chaos-ensued/
[15] Further commentary on the UK schools exams issues is contained in Ebsworth, Should algorithms be regulated like pharmaceuticals? https://www.techdotpeople.com/post/should-algorithms-be-regulated-like-pharmaceuticals
[16] https://www.sfchronicle.com/education/article/Elite-Lowell-High-School-admissions-would-become-15635273.php


